Hugging Face AutoTrain
3 minute read
Hugging Face AutoTrain is a no-code tool for training state-of-the-art models for Natural Language Processing (NLP) tasks, for Computer Vision (CV) tasks, and for Speech tasks and even for Tabular tasks.
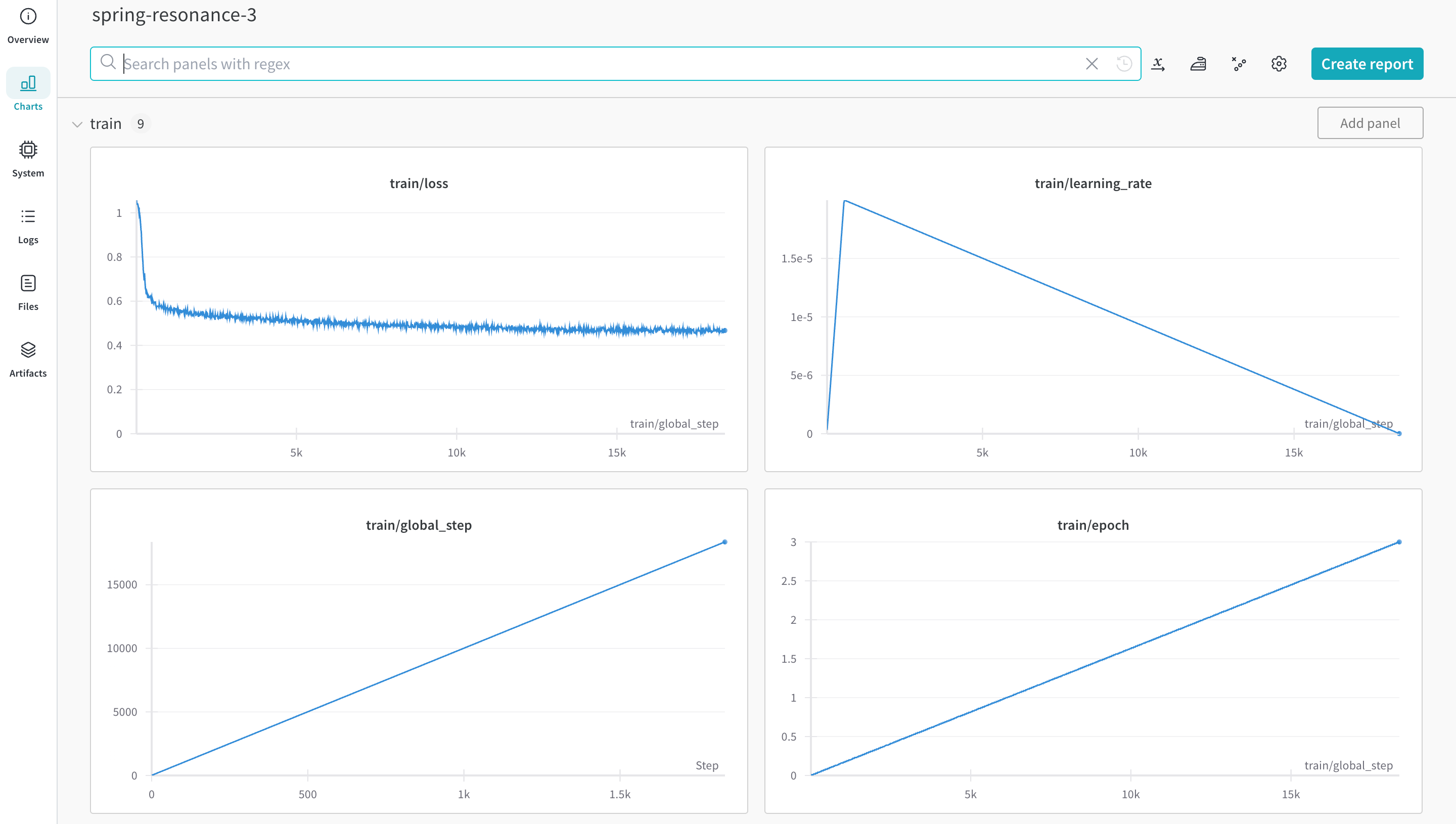
Weights & Biases is directly integrated into Hugging Face AutoTrain, providing experiment tracking and config management. It’s as easy as using a single parameter in the CLI command for your experiments
Install prerequisites
Install autotrain-advanced and wandb.
pip install --upgrade autotrain-advanced wandb
!pip install --upgrade autotrain-advanced wandb
To demonstrate these changes, this page fine-tines an LLM on a math dataset to achieve SoTA result in pass@1 on the GSM8k Benchmarks.
Prepare the dataset
Hugging Face AutoTrain expects your CSV custom dataset to have a specific format to work properly.
Your training file must contain a
textcolumn, which the training uses. For best results, thetextcolumn’s data must conform to the### Human: Question?### Assistant: Answer.format. Review a great example intimdettmers/openassistant-guanaco.However, the MetaMathQA dataset includes the columns
query,response, andtype. First, pre-process this dataset. Remove thetypecolumn and combine the content of thequeryandresponsecolumns into a newtextcolumn in the### Human: Query?### Assistant: Response.format. Training uses the resulting dataset,rishiraj/guanaco-style-metamath.
Train using autotrain
You can start training using the autotrain advanced from the command line or a notebook. Use the --log argument, or use --log wandb to log your results to a W&B run.
autotrain llm \
--train \
--model HuggingFaceH4/zephyr-7b-alpha \
--project-name zephyr-math \
--log wandb \
--data-path data/ \
--text-column text \
--lr 2e-5 \
--batch-size 4 \
--epochs 3 \
--block-size 1024 \
--warmup-ratio 0.03 \
--lora-r 16 \
--lora-alpha 32 \
--lora-dropout 0.05 \
--weight-decay 0.0 \
--gradient-accumulation 4 \
--logging_steps 10 \
--fp16 \
--use-peft \
--use-int4 \
--merge-adapter \
--push-to-hub \
--token <huggingface-token> \
--repo-id <huggingface-repository-address>
# Set hyperparameters
learning_rate = 2e-5
num_epochs = 3
batch_size = 4
block_size = 1024
trainer = "sft"
warmup_ratio = 0.03
weight_decay = 0.
gradient_accumulation = 4
lora_r = 16
lora_alpha = 32
lora_dropout = 0.05
logging_steps = 10
# Run training
!autotrain llm \
--train \
--model "HuggingFaceH4/zephyr-7b-alpha" \
--project-name "zephyr-math" \
--log "wandb" \
--data-path data/ \
--text-column text \
--lr str(learning_rate) \
--batch-size str(batch_size) \
--epochs str(num_epochs) \
--block-size str(block_size) \
--warmup-ratio str(warmup_ratio) \
--lora-r str(lora_r) \
--lora-alpha str(lora_alpha) \
--lora-dropout str(lora_dropout) \
--weight-decay str(weight_decay) \
--gradient-accumulation str(gradient_accumulation) \
--logging-steps str(logging_steps) \
--fp16 \
--use-peft \
--use-int4 \
--merge-adapter \
--push-to-hub \
--token str(hf_token) \
--repo-id "rishiraj/zephyr-math"
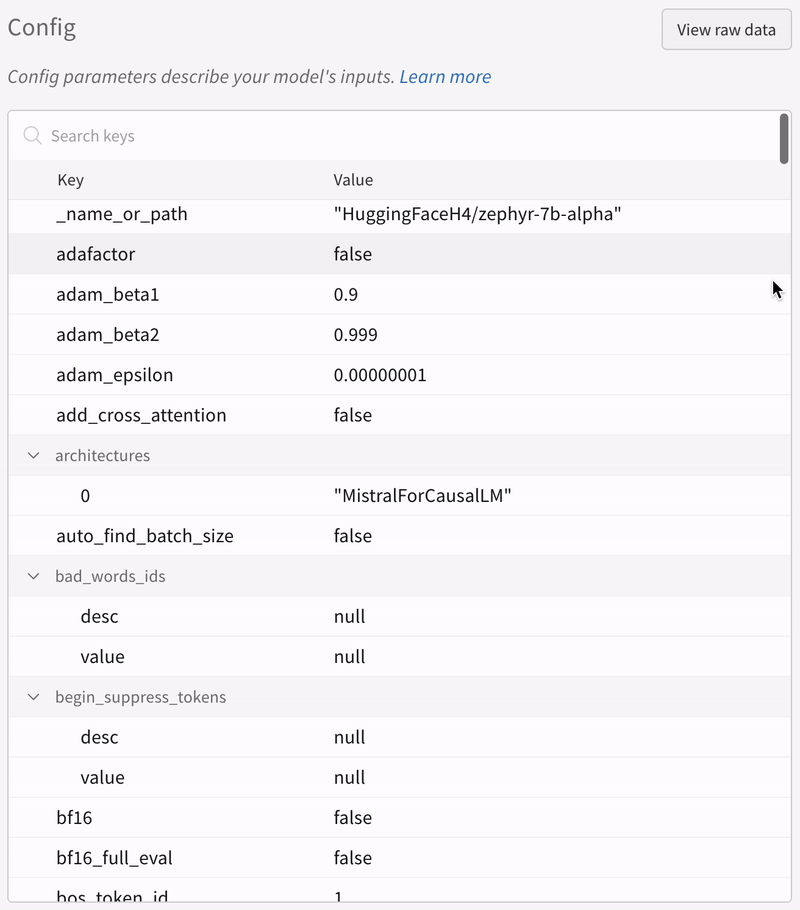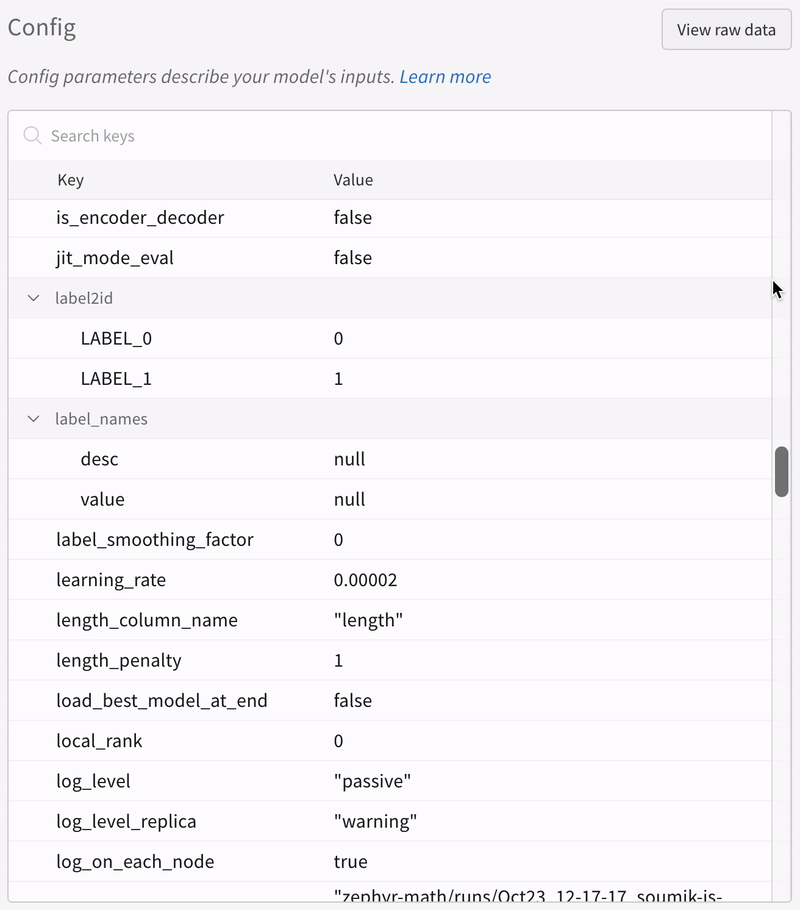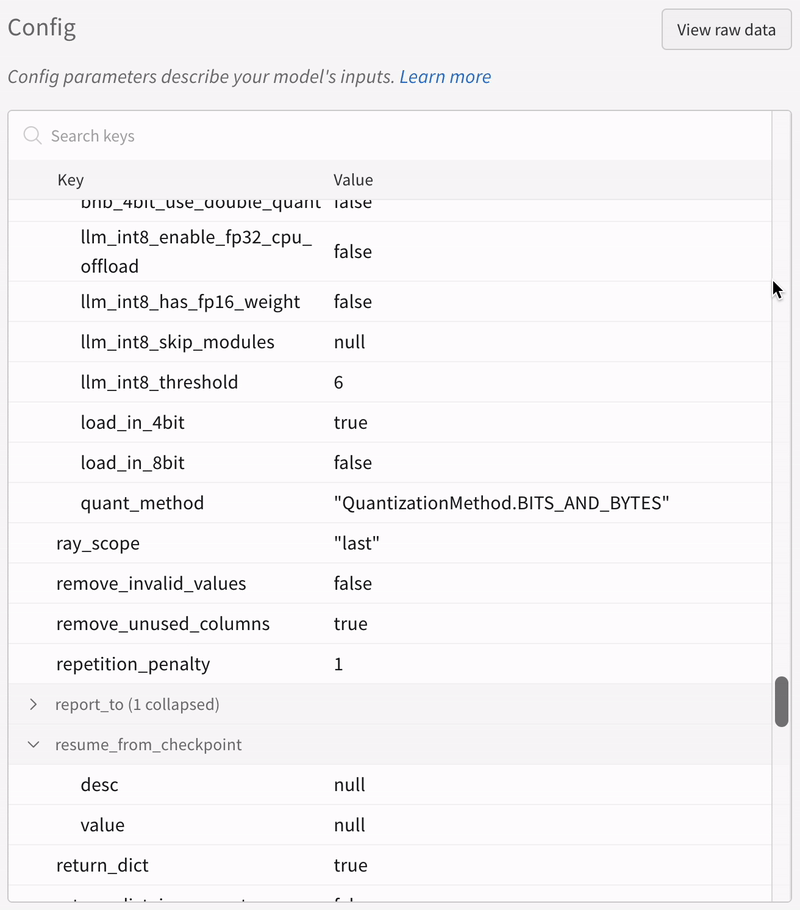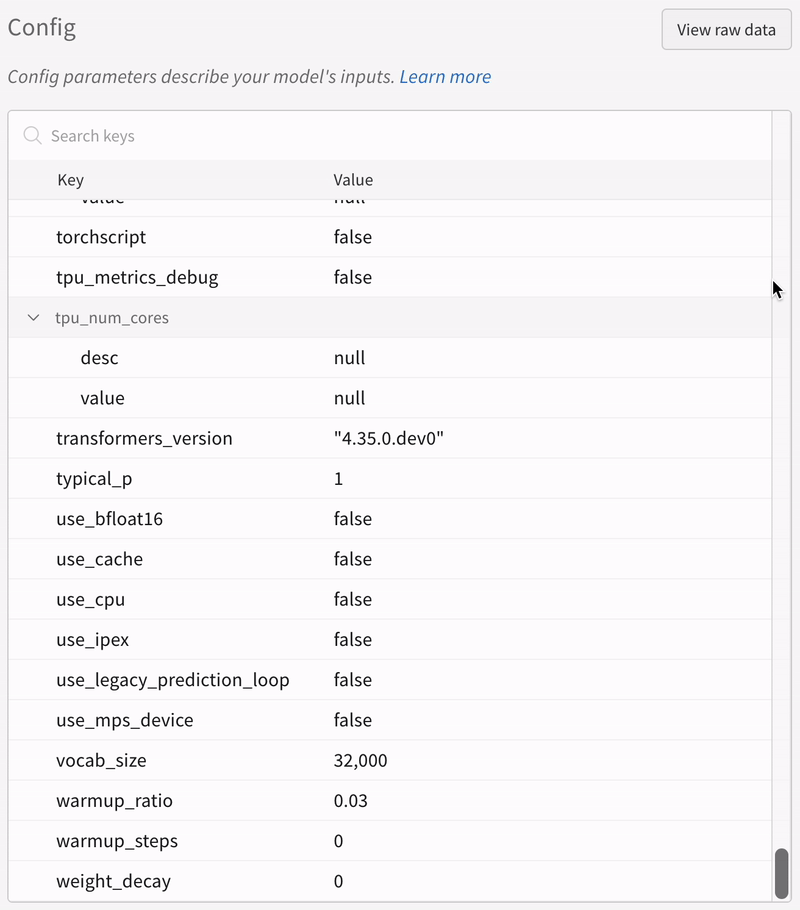
More Resources
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.